






Exploring Data Science Models
Discover diverse data science models. Explore machine learning, statistical analysis, predictive analytics, algorithms, data visualization & more

 Data science models are the backbone of modern decision-making processes across industries. By analyzing vast amounts of data, these models provide valuable insights that help businesses make informed choices, improve efficiency, and stay competitive in the market. Whether it's predicting customer behavior, optimizing resource allocation, or identifying trends, data science models play a crucial role in driving growth and innovation.
Data science models are the backbone of modern decision-making processes across industries. By analyzing vast amounts of data, these models provide valuable insights that help businesses make informed choices, improve efficiency, and stay competitive in the market. Whether it's predicting customer behavior, optimizing resource allocation, or identifying trends, data science models play a crucial role in driving growth and innovation.
Data science encompasses a range of techniques and tools used to extract meaningful information from data. Modeling is a key aspect of data science, involving the creation of mathematical representations that capture patterns and relationships within datasets. These models are then used to make predictions or optimize processes based on new data inputs.
Understanding Data Science Models
Data science models are mathematical representations used to extract insights and make predictions from data. They play a vital role in various industries by analyzing patterns and relationships within datasets, enabling informed decision-making, and optimizing processes. These models act as powerful tools for businesses to understand customer behavior, forecast market trends, and improve operational efficiency.
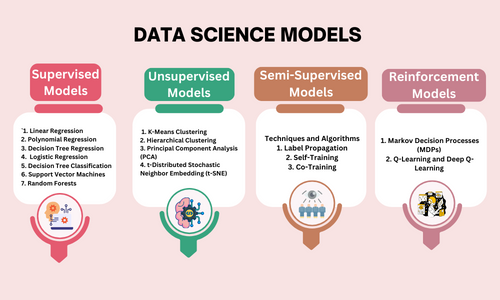
Types of Data Science Models
-
Supervised Learning Models: These models learn from labeled data, where the input and output are explicitly provided, allowing them to make predictions or classifications based on new data.
-
Unsupervised Learning Models: Unlike supervised models, unsupervised learning models work with unlabeled data to identify hidden patterns or structures within the data without predefined outputs.
-
Semi-Supervised Learning Models: These models combine elements of both supervised and unsupervised learning, leveraging a small amount of labeled data along with a larger pool of unlabeled data for training.
-
Reinforcement Learning Models: In reinforcement learning, agents learn to make decisions by interacting with an environment and receiving feedback in the form of rewards or penalties based on their actions.
Data science models find applications across various domains, including finance, healthcare, marketing, and cybersecurity. They are used for tasks such as fraud detection, personalized recommendations, medical diagnosis, and autonomous driving, revolutionizing industries and improving lives through data-driven insights and decision-making.
Supervised Learning Models
Supervised learning is a type of machine learning where the model is trained on labeled data, meaning the input data is paired with corresponding output labels. The goal is to learn a mapping function from the input to the output so that the model can make predictions or classifications on new, unseen data.
A. Regression Models
-
Linear Regression: Linear regression is a basic and widely used regression technique. It models the relationship between a dependent variable and one or more independent variables by fitting a straight line to the data.
-
Polynomial Regression: Polynomial regression extends linear regression by fitting a polynomial function to the data instead of a straight line. This allows for more complex relationships to be captured between the variables.
-
Decision Tree Regression: Decision tree regression involves partitioning the data into smaller subsets based on the values of the input features and fitting a simple model (like a constant) within each subset. It's particularly useful for non-linear relationships between variables.
B. Classification Models
-
Logistic Regression: Despite its name, logistic regression is a classification algorithm used for binary classification tasks. It models the probability of an event occurring using a logistic function and assigns data points to one of two classes based on this probability.
-
Decision Tree Classification: Similar to decision tree regression, decision tree classification partitions the data into subsets based on the values of the input features but is used for classifying data into multiple classes.
-
Support Vector Machines: Support vector machines (SVMs) are versatile classifiers that find the optimal hyperplane to separate data points into different classes while maximizing the margin between classes.
-
Random Forests: Random forests are ensemble learning methods that combine multiple decision trees to improve classification accuracy and reduce overfitting by averaging the predictions of individual trees.
Unsupervised Learning Models
A. Clustering Models
-
K-Means Clustering: K-means clustering groups similar data points into K clusters based on their features. It iteratively assigns points to the nearest cluster center and updates the center to minimize the distance between points in the same cluster.
-
Hierarchical Clustering: Hierarchical clustering organizes data into a tree-like structure of clusters. It either merges smaller clusters into larger ones (agglomerative) or divides larger clusters into smaller ones (divisive), creating a hierarchical relationship between clusters.
B. Dimensionality Reduction Models
-
Principal Component Analysis (PCA): PCA simplifies high-dimensional data by finding the most important features and transforming them into a lower-dimensional space. It helps retain the key information while reducing the complexity of the dataset.
-
t-Distributed Stochastic Neighbor Embedding (t-SNE): t-SNE visualizes high-dimensional data by representing each data point in a lower-dimensional space. It preserves the local structure of the data, emphasizing the relationships between nearby points in the original dataset.
Semi-Supervised Learning Models
Semi-supervised learning is a type of machine learning where the model is trained on a combination of labeled and unlabeled data. While labeled data has both input features and corresponding output labels, unlabeled data lacks explicit labels. Semi-supervised learning aims to leverage the available labeled data along with the vast amount of unlabeled data to improve the model's performance.
Techniques and Algorithms
-
Label propagation is a semi-supervised learning technique that assigns labels to unlabeled data based on the labels of neighboring data points in a graph or network. It propagates the labels from labeled data to unlabeled data through the relationships between data points.
-
Self-training is a simple semi-supervised learning approach where the model iteratively trains on the labeled data and then uses the trained model to predict labels for unlabeled data. The confident predictions are added to the labeled dataset, and the process repeats until convergence.
-
Co-training is a semi-supervised learning algorithm that trains multiple models on different subsets of features or views of the data. The models then collaborate to label unlabeled data points based on their perspectives, iteratively refining their predictions through mutual agreement.
Reinforcement Learning Models
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent takes action, receives feedback (rewards or penalties) from the environment, and learns to maximize its cumulative reward over time through trial and error.
A. Markov Decision Processes (MDPs)
Markov Decision Processes (MDPs) provide a mathematical framework for modeling sequential decision-making problems in reinforcement learning. An MDP consists of a set of states, actions, transition probabilities, and rewards. The agent's goal is to learn a policy—a mapping from states to actions—that maximizes its expected cumulative reward.
B. Q-Learning and Deep Q-Learning
Q-learning is a popular method for teaching computers how to make judgments. Estimating and checking determine the timing of actions to perform in various scenarios. It uses a specific function known as the Q-function to help it pick which actions to take. This function estimates how good each action is in a given situation based on the rewards the computer gets for taking those actions.
Deep Q-learning is like Q-learning but with an upgrade. Instead of using simple math to guess how good actions are, it uses deep neural networks, which are powerful tools for understanding complex patterns in data. These networks help the computer handle lots of information and make smarter decisions, even in very complicated situations. For example, Deep Q-Networks (DQN) uses deep neural networks to learn how to play video games or control robots, showing that they can handle tough challenges and make accurate decisions.
Model Evaluation and Selection
A. Metrics for Model Evaluation
-
Accuracy, Precision, and Recall: These metrics measure how well a model performs. Accuracy tells overall correctness; precision checks correctness in positive predictions; and recall assesses positive prediction completeness.
-
F1 Score: The F1 score combines precision and recall, offering a balanced measure of a model's performance, especially when positive and negative cases vary.
-
ROC Curve and AUC: The ROC curve displays trade-offs between true positive and false positive rates, while AUC summarizes overall model performance.
B. Cross-Validation Techniques:
Cross-validation checks how well a model generalizes to new data. Methods like k-fold cross-validation split data into subsets for training and testing.
C. Hyperparameter Tuning: Hyperparameters are preset model settings. Tuning them involves finding the best values to optimize model performance, often through techniques like grid search or random search.
Practical Applications of Models
Data science models are super useful in different industries. For example, predictive analytics helps companies predict future trends based on past data, which helps with planning. Recommender systems suggest stuff like movies or products you might like, making online shopping or streaming more personalized. Fraud detection models keep an eye out for any funny business in financial transactions, protecting both companies and customers from scams.
In real life, these models do cool stuff. Image classification models help computers recognize things in pictures, like identifying animals or objects in photos. Sentiment analysis checks how people feel about stuff by analyzing text, like figuring out if online comments are positive or negative. Customer segmentation divides customers into groups based on similarities, so companies can tailor their marketing to different types of customers, making everyone happier.
Difficulties and Considerations
In data science, two crucial challenges are overfitting (when a model learns too much from the training data) and underfitting (when a model is too simple to capture the data's complexity). Additionally, ensuring fairness in models and addressing biases is essential to preventing unfair outcomes, especially for different groups.
Moreover, models need to be interpretable and explainable, especially in sensitive areas, to understand how they make decisions. Lastly, the quality of data and feature engineering greatly influence model performance. Clean, relevant data and well-chosen features are vital for accurate and robust models. Balancing these considerations is key to building trustworthy and effective data science solutions.
In conclusion, we believe significant developments in data science include progress in deep learning for better understanding of complex data patterns, deeper integration of artificial intelligence (AI) and machine learning, particularly in tasks such as language understanding and image recognition, and a growing emphasis on ethical and responsible AI development to ensure fairness, transparency, and accountability in the deployment of AI techniques. It is critical to grasp the necessity of selecting the proper model for accurate and dependable results, as well as to continue exploring and learning about this ever-changing subject to contribute to its good progress and impact on technology and society.